GPU Compute
NVIDIA H100 GPU
Cost Effective Resources & Infrastructure
Reduce your cloud costs without sacrificing performance or reliability. mCloud delivers enterprise grade cloud infrastructure at a fraction of the cost of AWS, Google Cloud, or Azure.
Fault-Tolerant Tier IV Data Centre
Micron21 operates Australia’s first Tier IV-certified data centre, offering 100% uptime, redundant power, and high availability architecture.
24/7 Australian-based Expert Support
Our cloud specialists provide 24/7 Australian-based support, ensuring seamless deployments and efficient troubleshooting.
NVIDIA H100
Supercharge LLMs & AI
3,980 AUD / month
Minimum Specifications
Provided as a High-Availability mCloud Virtual Cloud Server
- GPU: NVIDIA H100 (80 GB)
- GPU Compute: Dedicated
- vCPU: 12 Cores - XEON Gold
- RAM: 64 GB - DDR4
- Storage: 500 GB - NVMe SSD
- Bandwidth: 2 TB p/m
- IP Address: Included
- DDoS Protection: Shield
Introduction
Securely Accelerate Workloads
From Enterprise to Exascale
H100 features fourth-generation Tensor Cores and a Transformer Engine with FP8 precision that provides up to 4X faster training over the prior generation for GPT-3 (175B) models.
For high-performance computing (HPC) applications, H100 riples the floating-point operations per second (FLOPS) of double-precision Tensor Cores, delivering 60 teraflops of FP64 computing for HPC while also featuring dynamic programming (DPX) instructions to deliver up to 7X higher performance.
With second-generation Multi-Instance GPU (MIG), built-in NVIDIA Confidential Computing, and NVIDIA NVLink Switch System, H100 securely accelerates all workloads for every data center, from enterprise to exascale.
Why Micron21
Why Choose Micron21 for GPU Compute?
Being Australia's first Tier IV data centre, you can rest assured our GPU Compute offerings provide reliable, secure, high-calibre performance.

High-Speed Compute &
NVMe SSD Storage
Our GPU Cloud Servers utilise Intel XEON Gold CPUs and ultra-fast NVMe SSDs to deliver high-performance compute and storage. These ensure ultra fast processing speeds and rapid access to resources for even the most-demanding of applications.

DDoS Protection
All GPU Cloud Servers with Micron21 are protected via our comprehensive DDoS platform which employs multiple layers of protection to inspect, scan and filter traffic at our global scrubbing centres.

Tier IV Data Centre
Tier IV is the highest uptime accreditation that a data centre can have. Ensure the availability of your systems by combining bulletproof dedicated servers with Micron21. We're Australia's first Tier IV accredited data centre.

ISO Certified
We're up-to-date with the latest in security standards. This includes being ISO 27001, 27002, 27018 and 14520 certified; PCI compliant; and IRAP assessed.

Data Sovereignty
We're proudly 100% Australian owned and operated. In this cyber age with concerns over foreign influence, the physical sovereignty of your data is the ultimate peace of mind.

Australian Support
Our dedicated Australian-based support technicians are located in the Micron21 Data Centre. We aim to completely remove the complexity of IT management for our customers with 24/7 access available.
Cloud GPUaaS
Cost Effective and High Performance
GPU-as-a-Service
Our mCloud platform offers the ability to integrate powerful NVIDIA GPUs directly into your virtual machines through GPU passthrough technology, allowing virtual machines to access the full capabilities of a physical GPU and providing near-native performance

Contended GPU
Through time-sliced access to GPU compute with guaranteed minimums, clients with non-time critical workloads or limited budgets can now get affordable access to cloud-based GPU compute
Dedicated GPU
For those who require their own dedicated GPUs, our platform supports NVIDIA A100, NVIDIA RTX A6000, NVIDIA H100, and NVIDIA H200 GPUs, all designed to support any workload you need to run in the cloud
Features
Key Features of NVIDIA H100 TensorCore GPUs
NVIDIA Ampere Architecture
Built with 80 billion transistors using a cutting-edge TSMC 4N process custom tailored for NVIDIA’s accelerated compute needs, H100 features major advances to accelerate AI, HPC, memory bandwidth, interconnect, and communication at data center scale
Transformer Engine
The Transformer Engine uses software and Hopper Tensor Core technology designed to accelerate training for models built from the world’s most important AI model building block, the transformer. Hopper Tensor Cores can apply mixed FP8 and FP16 precisions to dramatically accelerate AI calculations for transformers
NVLink Switch System
The NVLink Switch System enables the scaling of multi- GPU input/output (IO) across multiple servers at 900 gigabytes per second (GB/s) bidirectional per GPU, over 7X the bandwidth of PCIe Gen5. The system delivers 9X higher bandwidth than InfiniBand HDR on the NVIDIA Ampere architecture
NVIDIA Confidential Computing
NVIDIA H100 brings high-performance security to workloads with confidentiality and integrity. Confidential Computing delivers hardware-based protection for data and applications in use
Second-Generation Multi-Instance GPU (MIG)
The Hopper architecture’s second-generation MIG supports multi-tenant, multi-user configurations in virtualized environments, securely partitioning the GPU into isolated, right-size instances to maximize quality of service (QoS) for 7X more secured tenants
DPX Instructions
Hopper’s DPX instructions accelerate dynamic programming algorithms by 40X compared to CPUs and 7X compared to NVIDIA Ampere architecture GPUs. This leads to dramatically faster times in disease diagnosis, real-time routing optimizations, and graph analytics
Artificial Intelligence
Supercharge
Large Language Model Inference
With H100 NVL
For LLMs up to 70 billion parameters (Llama 2 70B), the PCIe-based NVIDIA H100 NVL with NVLink bridge utilizes Transformer Engine, NVLink, and 188GB HBM3 memory to provide optimum performance and easy scaling across any data center, bringing LLMs to the mainstream.
Servers equipped with H100 NVL GPUs increase Llama 2 70B model performance up to 5X over NVIDIA A100 systems while maintaining low latency in power-constrained data center environments
Conclusion
Experience GPU-Accelerated
Cloud Computing
Our mCloud platform, built on robust OpenStack architecture, now offers the ability to integrate powerful NVIDIA GPUs directly into your virtual machines through GPU passthrough technology. This allows virtual machines to access the full capabilities of a physical GPU as if it were directly attached to the system, bypassing the hypervisor’s emulation layer and providing near-native performance.
Enhance your cloud capabilities with GPU acceleration by integrating dedicated GPUs into your mCloud virtual machines and take your computing to the next level.
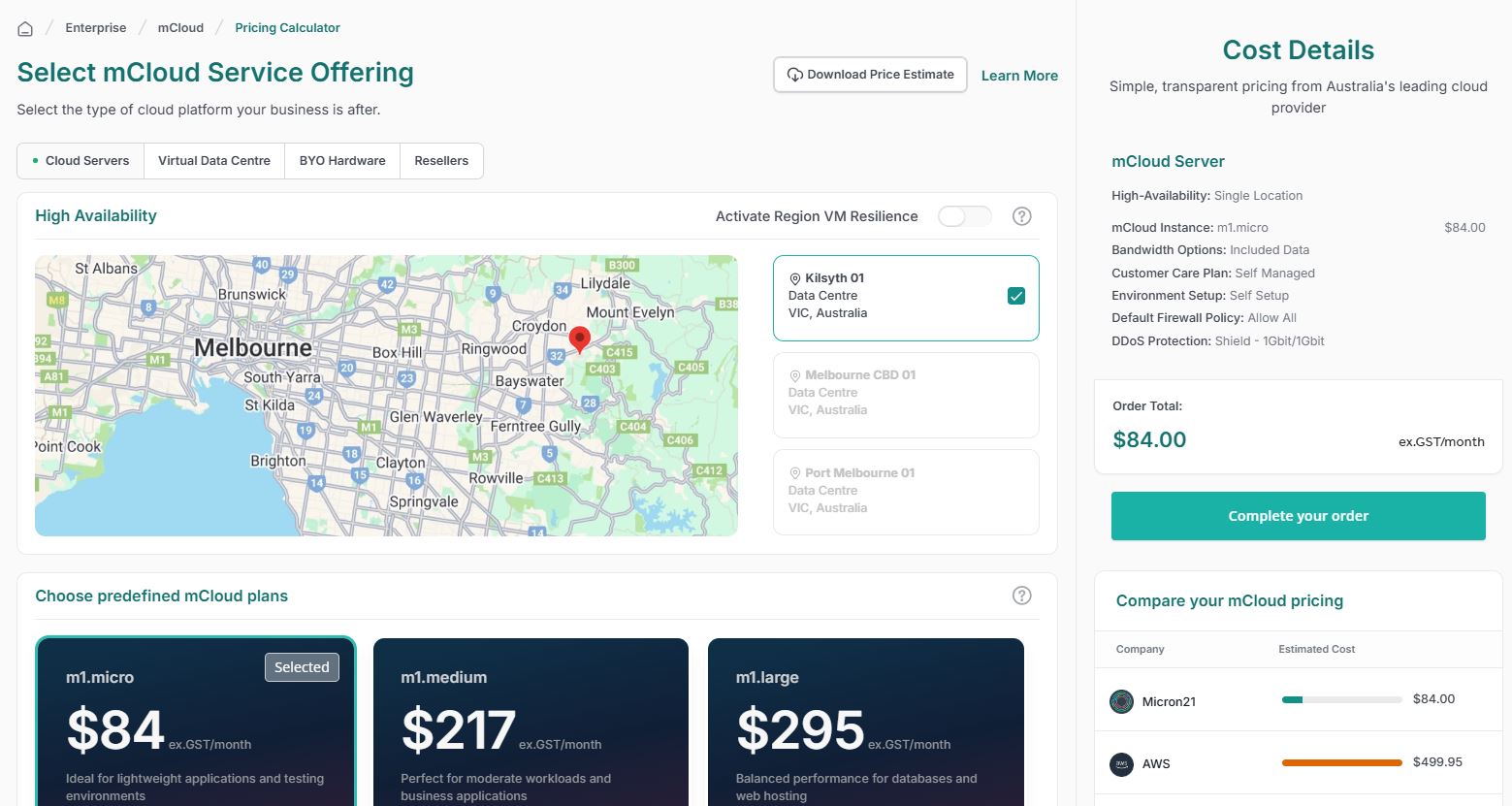
See How Much You Can Save with mCloud
Customize your cloud and compare costs instantly against AWS, Google Cloud, and Microsoft Azure. Get more for less with enterprise-grade performance.
- Transparent Pricing: No hidden fees or surprises.
- Enterprise-Grade for Less: High performance at lower costs.
- Instant Comparison: See real-time savings.